Context Switching & Long Running Docker Containers
TIL I messed up big time. Handling long running processes juggling between CPU cores on a dual socket system.
I’m going through updating post meta and I just saw this post. I’m going to rap a quick memory dump.
I have since upgraded to higher frequency broadwells. Two things were apparent from this change.
- Higher frequency helped massively with in-game latency. More than expected.
- Broadwell has basically fixed all of the issues that I had.
The reason being that the older CPUs had some Spectre mitigations in-place which flushed the cache to avoid exploitation. This meant that context switching added slight latency.
We did have some issues with Genesis 2 because it’s such a poorly optimized map. When players build in water cube, latency would go through the roof. It’s just cube. Nowhere else. Pinning CPU for Genesis 2 helped a lot.
So there’s still some validity to CPU pinning. It can help to avoid context switches. CPU affinity/pinning in this way did not help though. But pinning the process on the host definitely did easy latency.
You can minmax old hardware all you want. Use this as a mitigation strategy. However invest in broadwell or newer CPUs, or just go Ryzen. We’ve also had fantastic experiences on desktop CPUs however their density doesn’t suit the DC.
This did not work
The basic theory behind what I was doing was this;
- My long-running, single threaded processes jumped between CPU cores, known as context switching
- This was causing lag spikes because I run an old Intel architecture
- Set CPU affinity on the processes and dedicate those cores to those processes
My theory was that the Ark processes states were being saved and instantly resumed on other cores. If one map was ‘not doing much’ and another map was ‘doing much more’, then my theory was that Linux/Docker was saving the state of the ‘not doing much map’ and then realizing that it was doing more than it originally though, then instantly resuming it on another free core. Kind-of like a hot potato of processes.
Unfortunately, it’s not that simple. I am now soberly rereading what I had written and while the logic does check out, CPU’s are unfortunately not as simple minded as myself and this little theory did not pan out sadly.
Needless to say; CPU affinity will not improve the performance of your older Intel CPUs when running long running processes. I have since resorted to buying E5 2667 v2’s for my server.
Today I learned something new. Today, I finally found enough time to figure out why my Node Exporter dashboard in Grafana couldn’t pull from my remote server.
TL;DR on the Grafana issue; the dashboard that I use has the ability to switch between data sources. Unfortunately, the dashboard hard codes the data sources into the graphs on import, which means switching between data sources will update the host but not the data source to pull the host data from in the graphs. Very frustrating. Instead of contributing to an open source dashboard and fixing the issue, I just have two dashboards, because I’m time poor.
Moving on: I noticed two things in my graphs that piqued my interest;
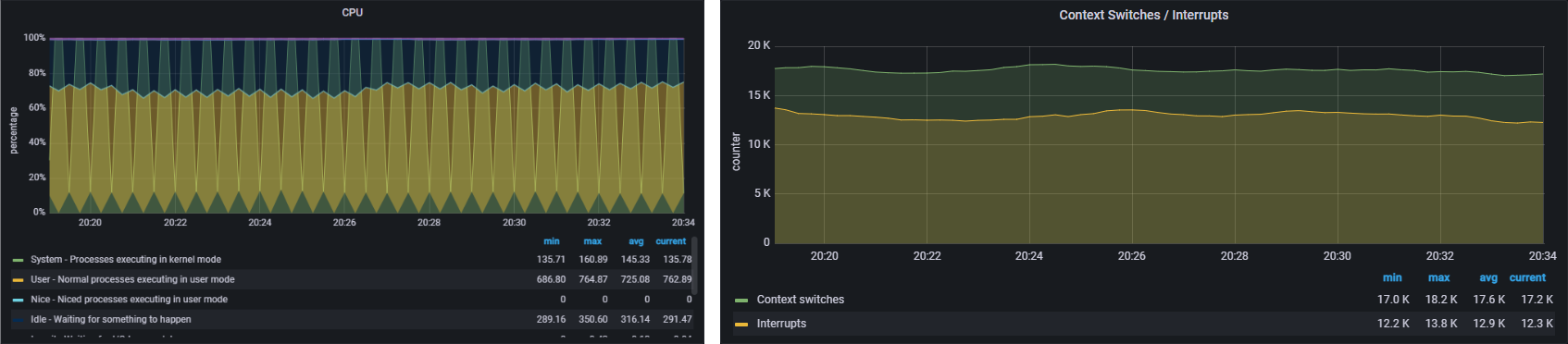
Firstly, we have this curiously spiking yet not spiking of the CPU cores. That’s not really all that interesting in of itself because these Docker images get hammered constantly; the interesting part is the context switching. I haven’t had to deal with context switching before because I haven’t really run a lot of Sandy Bridge gear, however I have been informed by Pikachu that Coffee Lake and earlier processors suffer performance issues with context switching following the remedies of the meltdown/spectre attacks.
Having to actually care about this is new to me because I have only ever had to care about short-lived child processes that are created/killed as needed; long running processes aren’t something that I have generally had to concern myself with. Now that the Ark population is growing and players are doing boss battles and increasing entity counts, the servers are starting to test that 1Gb connection and older generation CPU architecture (and I bought the slow one too). Because Ark processes are long-lived things, it’s going to be important that I know how to care for these beloved processes in order to reduce the ‘noise’ in my Discord whenever there’s excessive lag.
One of the major pain points is sadly Genesis and Gensis 2. If you’re an Ark player or server admin, you’ll be (totally not) surprised to know that the boss battles on these maps are extremely lag sensitive and lag inducing. Interestingly, boss battles don’t cause a lot across the map. I don’t know if this is because multithreading was released since writing this article or if this is because of something else, but it’s a little bit of a life saver.
Checking CPU affinity
Firstly, I need to confirm that my Docker containers are not pinning to a single CPU core. If they’re hopping cores, that alone might be enough to increase the in-game latency (theoretically speaking). You check check a tasks affinity by pulling the process ID with ps and using taskset to output that pids affinity:
root@dodo:~# taskset -c -p 70982
pid 70982's current affinity list: 0-11
Secondly, I need to confirm that Ark processes are indeed jumping CPU and that means that I need to catch them in the act. This took me all of 1 second because it happened right before my eyes:
root@dodo:~# ps -o pid,psr,comm -p 70982
PID PSR COMMAND
70982 5 ShooterGameServ
root@dodo:~# ps -o pid,psr,comm -p 70982
PID PSR COMMAND
70982 6 ShooterGameServ
root@dodo:~# ps -o pid,psr,comm -p 70982
PID PSR COMMAND
70982 6 ShooterGameServ
So we have proven that the Arks are playing musical vCPU cores while we’re trying to enjoy a night of being brutally punshing by a game. For bonus points, you can actually use htop to watch this behavior. While writing this, the CPU changed every second. Simply press F10 and change the columns to include PROCESSOR.
What could happen if I change CPU affinity
The original idea was to tie each Docker container to a single CPU and impose a memory limit on a per-container basis. I had issues getting the restrictions to stick and because it’s just personal a game server, I could quite frankly give two shits if they lag when someone loads into the Manticore. I never really bothered putting this in place, and I figured that Docker would just sort itself out. In fairness, it kind-of is.
We have two possible scenarios that could occur from CPU pinning;
- Long running processes stop competing for CPUs, reducing context switching and reducing overall server lag
- CPU pinning causes wait time increases leading to increased lag
I’m gunning for the former.
Pinning Docker Containers
There are two ways to do this; the easy way, and the proper way. I am obviously going to opt for the easy way because I’m about 6 shots deep however you can google ‘cgroups’ if you want to do things properly.
The easy way is to just edit my docker-compose file:
services:
service:
cpuset: "n"
In context:
services:
service-1:
cpuset: "0"
service-2:
cpuset: "1"
service-3:
cpuset: "2"
If you’re doing something tricky with things then I cannot help you. I am specifically running 12 vCPUs on this system to run 12 long running processors. My environment is extremely controlled in this regard. It would be better to have 13 vCPU’s and have 1 for system and 1 for each container, however I dont have time to suffer a VM reboot; a Docker restart is probably the limit of my tolerance at 10pm at night.
What Happened
THE LAG BECOME WORST.